SpringBoot
1,SpringBoot启动流程
1,从main方法中找到run方法,执行run方法之前创建一个SpringApplication对象
2,进入run方法,创建应用监听器 SpringApplicationRunListeners
3,加载SpringBoot配置环境 ConfigurableEnvironment
4,加载应用上下文 ConfigurableApplicationContext 当做run方法的返回对象
5,最后创建Spring容器 refreshContext,实现starter自动化配置和实例化bean等

2,SpringBoot自动装配
1,启动类上@SpringBootApplication注解
2,包含
@SpringBootConfiguration (标记是一个主配置类)
@ComponentScan (包扫描加载bean)
@EnableAutoConfiguration (开启自动装配)
@Import({AutoConfigurationImportSelector.class})给容器中导入组件
该类中有selectImports()方法
最后调用SpringFactoriesLoader.loadFactoryNamesf加载META-INF/spring.factories文件
将这些值添加到容器中,用这些类做自动配置
3,配置文件读取优先级
项目启动后扫描顺序:
根目录/confing目录 > 根目录 > resources/config目录 > resources目录 > properties > yml
4,定义Bean的方式
1,@Configuration和@Bean注解
2,@Component等派生注解
3,基于xml配置bean spring.xml
5,SpringBoot依赖注入三种方式
1,基于构造方法的依赖注入
2,基于setter的依赖注入
3,使用注解来进行依赖注入
Spring
1,Spring事务如何实现的
两种方式:声明式(基于@Transactional注解,一般用这种)和编程式(编程方式TransactionTemplate处理业务)
1,Spring事务底层是基于数据库事务和AOP机制的
2,对使用的Transactional注解的bean,spring会创建一个代理对象作为Bean
3,当代理对象调方法时,判断方法上是否有Transactional注解
4,如果有Transactional注解,则会利用事务管理器(PlatformTransactionManager->DataSourceTransactionManager)
创建一个数据库连接
5,并且修改数据库连接的autocommit属性为false,禁止自动提交
6,然后执行当前方法,方法中会执行sql
如果中间需要调用别的方法,需要配置好需要的事务传播机制
默认的传播机制就是REQUIRED,继续用存在的数据库连接
7,执行完当前方法后,如果没有出现异常就直接提交事务
8,如果出现了异常,并且这个异常(注解属性rollbackFor设置异常范围)是需要回滚的就会回滚事务,否则仍然提交事务
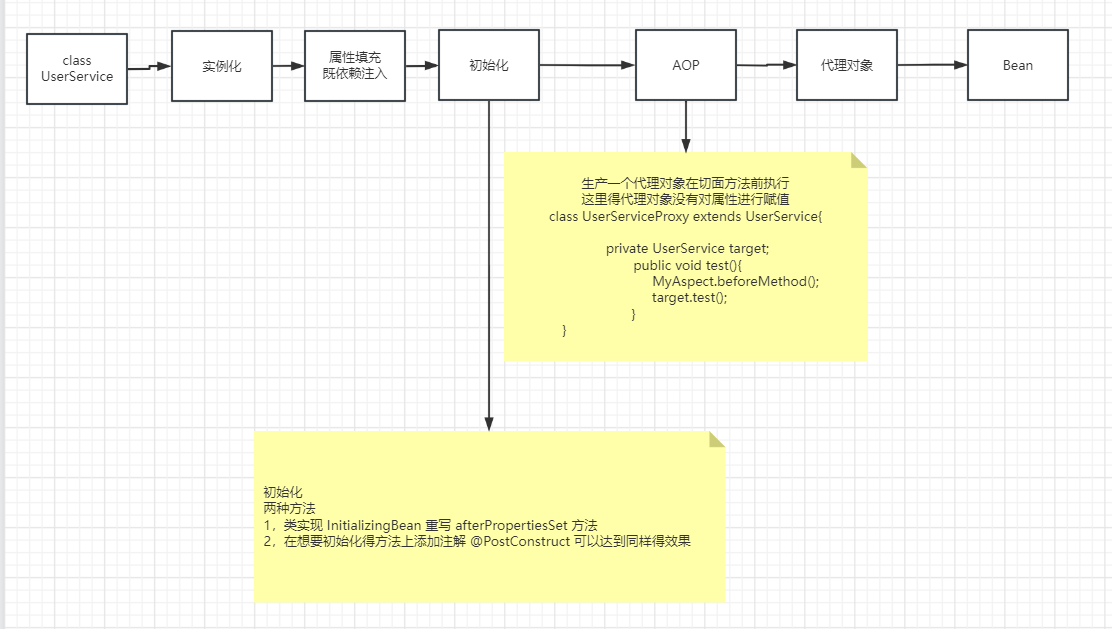
2,Spring生命周期
3,@Transactional注解的失效场景
1,在同一个类中方法调用,导致 @Transactional 失效
2,rollbackFor 设置错误
3,异常被try catch处理了,导致 @Transactional 没办法回滚而失效
4,注解应用在非 public 修饰的方法上,不支持回滚
4,怎么解决循环依赖
三级缓存解决循环依赖
- singletonObjects:用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用
- earlySingletonObjects:创建了一半的对象放在容器Map中,实例化未初始化
- singletonFactories:单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖
1,我们可以使用注解@Lazy(解决构造方法造成的循环依赖)
2,spring使用三级缓存(map)解决
一级缓存(完整的对象): singletonObjects存储的是所有创建好了的单例Bean,
二级缓存(半成品对象):earlySingletonObjects存储的是实例化未初始化的对象,
三级缓存(bean工厂):singletonFactories提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象,

5,分布式事务怎么实现
CAP理论(c一致性 a可用性 p容c性)
CAP理论是分布式事务处理的理论基础,分布式系统在设计时只能满足两种,无法兼顾三种。
分布式事务一致性解决方案
1,两阶段提交协议(2PC),(2PC效率很低,对高并发很不友好)
第一阶段:准备阶段(prepare)
第二阶段:提交(commit)/回滚(rollback)阶段
2,事务补偿 TCC,是基于2PC实现的业务层事务控制方案(Try,Confirm,Cancel)
以在线下单为例
Try阶段会去扣库存
Confirm阶段则是去更新订单状态
如果更新订单失败,则进入Cancel阶段,会去恢复库存。
3,消息队列实现最终一致性
项目问题
1,你在项目中用到过那些设计模式
1,工厂模式
文件存储:七牛云,腾讯云,阿里云,本地,用工厂模式在配置文件中可以方便切换使用那个对象存储引擎
2,策略模式(解决if过多,更方便扩展)
支付方式:微信的js支付,native,app,支付宝的一些支付方式,使用策略模式更方便扩展
3,抽象父类模板方法+工厂+策略 行业缴费
父类提供定义公共的方法
工厂多种实现处理类
策略根据规则找到对应的实现类
责任链模式:对下载的三方账单进行一系列的处理(文件的移动,重命名,文件的过滤,加密,生成ok文件)
2,项目中遇到的问题
1,闸机二维码,提前入场,延迟出场,这里用到了对redis key的监听
2,视频完整性,防止当日网络问题,服务重启等问题,视频采集的不完整,定时任务实现视频补偿机制
日夜颠倒头发少 ,单纯好骗恋爱脑 ,会背九九乘法表 ,下雨只会往家跑 ,搭讪只会说你好 ---- 2050781802@qq.com


