MySQL
数据回滚
binlog 未启用
SHOW VARIABLES LIKE 'log_bin';
OFF关闭 ON开启
##查看binlog
SHOW BINARY LOGS;
##清理MySQL二进制日志
PURGE BINARY LOGS BEFORE NOW();
调整 binlog 保留时间
SET GLOBAL binlog_expire_logs_seconds=604800; # 保留7天
将 MySQL binlog 文件转换为可读格式
-vv 显示更详细的信息
##只解码特定数据库的日志
mysqlbinlog -d your_database_name /var/lib/mysql/binlog.000011 > db_binlog.txt
## 显示更详细的信息
mysqlbinlog -vv /var/lib/mysql/binlog.000011 > verbose_binlog.txt
##过滤life_record之后的11行数据
mysqlbinlog -vv /var/lib/mysql/binlog.000011 | grep -A 11 "life_record" > update_operation.txt
##按时间范围提取
mysqlbinlog -vv --start-datetime="2024-06-18 10:00:00" --stop-datetime="2024-06-22 12:00:00" /var/lib/mysql/binlog.000011 >update_operation.txt
查看转换后的内容
# at 12345
#240620 14:30:00 server id 1 end_log_pos 12456 CRC32 0xabcd1234
SET TIMESTAMP=1718869800/*!*/;
BEGIN
/*!*/;
# at 12456
#240620 14:30:01 server id 1 end_log_pos 12567 CRC32 0xefgh5678
UPDATE `your_db`.`your_table`
SET `name` = 'new_value'
WHERE `id` = 100
/*!*/;
# at 12567
#240620 14:30:02 server id 1 end_log_pos 12678 CRC32 0ijkl9012
COMMIT/*!*/;
查询当天、昨天、上周、本月、上一季、本年的SQL语句
**今天 **
select * from 表名 where to_days(时间字段名) = to_days(now());
昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1;
近7天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名);
近30天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名);
本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' );
上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1;
查询本季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
查询上季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
查询本年数据
select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
查询上年数据
select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
查询当前这周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
查询上周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
查询当前月份的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(now(),'%Y-%m')
查询距离当前现在6个月的数据
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
统计距今3个月每个月数据
select DATE_FORMAT(release_time, '%Y-%m') as createDate,count(id) as count
from productlist where release_time >= DATE_SUB( CURRENT_DATE() , INTERVAL 2 MONTH ) group by createDate order by createDate desc
统计过去12个月每月数据
select DATE_FORMAT(release_time, '%Y-%m') as createDate,count(id) as count
from productlist group by createDate order by createDate desc limit 12
sum(case when then else end)的用法
Case具有两种格式。简单Case函数和Case搜索函数。Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略
# 简单Case函数
CASE
WHEN name IN( '小明', '小红') THEN '第一类'
WHEN name IN ('小红') THEN '第二类'
ELSE '其他' END
# CASE WHEN 类似于搜索
SELECT YEAR,
sum( CASE WHEN month = 1 THEN amount ELSE 0 END ) AS m1,
#sum和case结合,实现分段统计,如果month=1, #sum+=amount的值,否则sum+0;得出的结果以m1为列名。
sum( CASE WHEN month = 2 THEN 1 ELSE 0 END ) AS m2,
#sum和case结合,实现分段统计,如果month=2, # sum+=1 的值,否则sum+0;得出的结果以m1为列名。
sum( CASE WHEN month = 3 THEN 1 ELSE 0 END ) AS m3,
sum( CASE WHEN month = 4 THEN 1 ELSE 0 END ) AS m4
FROM
sales
group by
year
复制表结构及数据到新表
包含主键、索引、分区等
-- 首先
CREATE TABLE 新表 LIKE 旧表
-- 然后
INSERT INTO 新表 SELECT * FROM 旧表
Sql执行循序
FROM where,group by,having,SELECT,order by
我(W)哥(G)是(SH)偶(O)像
FROM:确定查询的数据来源(表或子查询)。
ON:应用连接条件(仅适用于 JOIN 操作)。
JOIN:根据连接条件合并表。
WHERE:过滤符合条件的行。
GROUP BY:对数据进行分组。
HAVING:过滤分组后的数据。
SELECT:选择要返回的列。
DISTINCT:去除重复行。
ORDER BY:对结果进行排序。
LIMIT/OFFSET:限制返回的行数或分页。
尽量用小表去匹配大表
MVCC解决的问题?
多版本并发控制
数据库并发场景:
1,读读:不存在安全问题,不需要并发控制
2,读写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读问题
3,写写:有线程安全问题,可能存在更新丢失问题
MVCC是一种用来解决读写冲突的无锁并发控制,也就是为事务分配单项增长的时间戳,为每一个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据快照,所以MVCC可以为数据库解决以下问题
1,在并发读写数据库时,可以做到在读操作时不用堵塞写操作,写操作也不用堵塞读操作,提高数据库并发读写性能
2,解决脏读,幻读,不可重复读等事务隔离性问题,但不能解决更新丢失问题
慢查询日志
也既 慢sql
MySQL慢查询日志英文全称:Slow Query Log ,即 慢查询日志,主要是记录一些查询执行较慢的 SQL 语句。
这个日志非常常用,主要是给开发者调优用的。MySQL慢查询日志可监控有效率问题的SQL语句 。
注意:MySQL慢日志记录执行时间过长和没有使用索引的查询语句,报错select、update、delete以及insert语句,慢日志只会记录执行成功的语句。
可以通过 explain 命令来查看
-- LEFT JOIN
EXPLAIN SELECT * FROM `tag` LEFT JOIN `tagmap` on `tagmap`.`tag_id` = `tag`.`id` WHERE `article_id` = 7

-- 优化 使用 INNER JOIN
EXPLAIN SELECT * FROM `tag` INNER JOIN `tagmap` on `tagmap`.`tag_id` = `tag`.`id` WHERE `article_id` = 7

可以清楚的看到,优化后:Extra那里为NULL,已经没有Using where了。
当然了,**select *** 也是不允许的
expain的信息有12列
id:选择标识符;在一个大的查询中每一个查询关键字都对应一个id
select_type:表示查询的类型
table:输出结果集的表
partitions:匹配的分区;提供有关表分区的信息
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较;当索引列等值查询时,与索引列进行等值匹配的对象信息
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比;某个表经过搜索条件过滤后剩余记录条数的百分比
Extra:执行情况的描述和说明
注意:
如果MySQL的Explain结果中Extra为空值代表SQL语句不用优化,性能还可以。当然了,一条好的SQL语句不能只看Extra,还要看type等其它字段,都是综合考
虑的。
具体如下
https://www.fujieace.com/mysql/explain.html
聚合函数
FIND_IN_SET(str,strlist)
str 要查询的字符串
strlist 字段名 参数以”,”分隔
查询字段(strlist)中包含(str)的结果,返回结果为null或记录
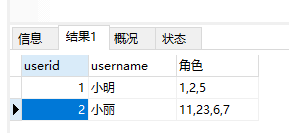
SELECT userid,username,userrole 角色 FROM `user` WHERE find_in_set('2',userrole)
批量更新
<update id="batchUpdate" parameterType="java.util.List">
<foreach collection="list" item="user" separator=";">
UPDATE user_table
SET column1 = #{user.column1},
column2 = #{user.column2}
WHERE id = #{user.id}
</foreach>
</update>
MySQL 存储过程
MySQL事务
基本要素(ACID)
原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做
一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏,要么都c要么都失败
隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰
持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚
innodb事务包含:
redo log 重做日志,提供前滚操作,保证事务的持久性
undo log 回滚日志,提供回滚操作,保证事务的原子性
MySQL 索引
聚簇索引和非聚簇索引区别
- 聚簇索引叶子节点存储的是行数据;而非聚簇索引叶子节点存储的是聚簇索引(通常是主键 ID)。
- 聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,因此性能不如聚簇索引。
- 聚簇索引一般为主键索引,而主键一个表中只能有一个,因此聚簇索引一个表中也只能有一个,而非聚簇索引则没有数量上的限制。
普通索引
主键索引
主键是具有唯一性并且不允许为NULL
复合索引
也叫组合索引,使用最左原则
全文索引
主要用来查找文本中的关键字
索引的数据结构
B+Tree,innodb默认索引数据结构是B+Tree
B树:每个节点大小相同,节点排序,一个节点可以存多个元素,多个元素也排序了,每个节点左边比该节点小,右边比该节点大
B+树:拥有B树的特点,非叶子节点不再存储数据,所有的叶子节点都有一个双向的指针,做了一个双向链表,更方便全表扫描,范围查找等SQL语句
mysql中一个innodb页就是一个节点,默认16kb。

索引设计原则
查询更快,占用空间更小
1)数据量小的表,建立索引效果较差,没必要建索引
2)不要过度索引,索引会使用磁盘空间
3)更新频繁的字段不时候建立索引
什么是MVCC?
多版本并发控制,主要是为了提高数据库的并发性能
同一行数据平时发生读写请求时,会上锁阻塞住。但mvcc用更好的方式去处理读—写请求,做到在发生读—写请求冲突时不用加锁。
这个读是指的快照读,而不是当前读,当前读是一种加锁操作,是悲观锁。
数据库事务隔离级别
1、READ-UNCOMMITTED(读取未提交)
最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
2、READ-COMMITTED(读取已提交)
允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
3、REPEATABLE-READ(可重复读) 默认
一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,但是不能看到其他事务对已有记录的更新(即晚于本事务开始的)
(事务A刚开始查询,另一个事务B之后开始更新,则A查询的数据还是未更新前的数据)
对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
4、SERIALIZABLE(可串行化)
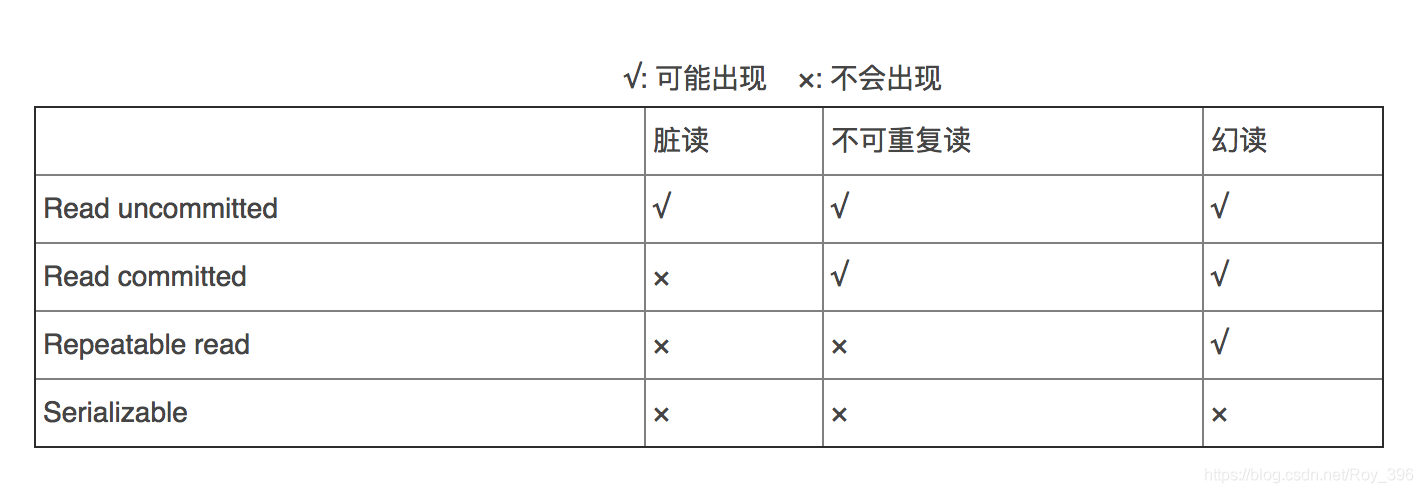
参考 https://blog.csdn.net/Roy_396/article/details/116896957
MySQL为什么会选择可重复读作为默认隔离级别?
在Oracle,SqlServer中都是选择读已提交(Read Commited)作为默认的隔离级别,MySQL选择的是可重复读
MySQL主从复制的时候,读已提交隔离级别把数据同步到从库时,会出现数据不一致问题,而在可重复读的隔离级别下因为有间隙锁的存在,不会发生数据不一致问题
为什么互联网公司选择使用 RC?
并发度:读已提交 > 可重复读
读已提交还支持半一致读
主从复制
MySQL在主从复制的过程中,数据的同步是通过bin log进行的
简单理解就是主服务器把数据变更记录到bin log中,然后再把bin log同步传输给从服务器,从服务器接收到bin log之后,再把其中的数据恢复到自己的数据库存储中
binlog 三种格式 :statement、row、mixed
读已提交:只支持row格式
可重复读:支持三种格式statement、row、mixed
MySQL 锁
按粒度分
1,行级锁:锁住某行,粒度小,并发高,(Innodb默认)
2,表级锁:锁住某页,粒度大,并发小 (MyISAM)
3,间隙锁:锁的是一个区间,介于行锁,表锁之间
按锁的兼容性分
1,共享锁:既读锁,一个事务给某行加了读锁,其他事务也可以读,但是不能写
2,排他锁:既写锁,一个事务给某行加了写锁,其他事务不能读,也不能写
并发控制策略分 还可以分为
1,乐观锁:通过一个版本号控制
2,悲观锁:行锁,表锁既悲观锁
事务的隔离级别中,通过锁来解决幻读问题
读取表的信息
-- 1. 根据库名获取所有表的信息
-- 使用以下SQL语句来获取指定数据库中所有表的信息:
SELECT * FROM information_schema.`TABLES` WHERE TABLE_SCHEMA='kva-admin-db';
-- 其中,“your_database”是你要查询的数据库名称。这条语句将返回一个包含所有表信息的数据表。
-- 2. 根据库名获取所有表名称和表说明
-- 使用以下SQL语句来获取指定数据库中所有表的名称和注释:
SELECT TABLE_NAME, TABLE_COMMENT FROM information_schema.`TABLES` WHERE TABLE_SCHEMA='kva-admin-db';
-- 这条语句将返回一个包含表名和注释的数据表。
-- 3. 根据库名获取所有的字段信息
-- 使用以下SQL语句来获取指定数据库中所有表的所有字段信息:
SELECT
TABLE_SCHEMA AS 'schema',
TABLE_NAME AS 'tablename',
COLUMN_NAME AS 'cname',
ORDINAL_POSITION AS 'position',
COLUMN_DEFAULT AS 'cdefault',
IS_NULLABLE AS 'nullname',
DATA_TYPE AS 'dataType',
CHARACTER_MAXIMUM_LENGTH AS 'maxLen',
NUMERIC_PRECISION AS 'precision',
NUMERIC_SCALE AS 'scalename',
COLUMN_TYPE AS 'ctype',
COLUMN_KEY AS 'ckey',
EXTRA AS 'extra',
COLUMN_COMMENT AS 'comment'
FROM information_schema.`COLUMNS`
WHERE TABLE_SCHEMA='kva-admin-db'
ORDER BY TABLE_NAME, ORDINAL_POSITION;
-- 这条语句将返回一个包含所有字段信息的数据表。
-- 4. 根据库名获取所有的库和表字段的基本信息
-- 使用以下SQL语句来获取指定数据库中所有表和字段的基本信息:
SELECT C.TABLE_SCHEMA AS 'schema',
T.TABLE_NAME AS 'tablename',
T.TABLE_COMMENT AS 'tablecomment',
C.COLUMN_NAME AS 'columnname',
C.COLUMN_COMMENT AS 'columncomment',
C.ORDINAL_POSITION AS 'position',
C.COLUMN_DEFAULT AS 'columndefault',
C.IS_NULLABLE AS 'nullname',
C.DATA_TYPE AS 'dataType',
C.CHARACTER_MAXIMUM_LENGTH AS 'maxlen',
C.NUMERIC_PRECISION AS 'precision',
C.NUMERIC_SCALE AS 'scale',
C.COLUMN_TYPE AS 'ctype',
C.COLUMN_KEY AS 'ckey',
C.EXTRA AS 'extra'
FROM information_schema.`TABLES` T
LEFT JOIN information_schema.`COLUMNS` C ON T.TABLE_NAME=C.TABLE_NAME AND T.TABLE_SCHEMA=C.TABLE_SCHEMA
WHERE T.TABLE_SCHEMA='kva-admin-db'
ORDER BY C.TABLE_NAME, C.ORDINAL_POSITION;
日夜颠倒头发少 ,单纯好骗恋爱脑 ,会背九九乘法表 ,下雨只会往家跑 ,搭讪只会说你好 ---- 2050781802@qq.com


